Lifecycle Marketing Data Dependency: How to Fix It
2 in 5 lifecycle teams manually export audience lists by hand. 1 in 2 can't build a segment without a data team queue. Here's why it happens and how to fix it.
Abhimanyu
·
New York
·

There's a conversation that happens in almost every growth team:
Marketing: "We need to launch a re-engagement campaign for users who haven't hit their first value moment."
Data: "Sure, we can get to that — probably next week?"
Probably next week is quietly killing your retention numbers.
Your lifecycle team has the strategy and the creative. Your data team has the customer intelligence locked in a warehouse. Between them sits a bottleneck that no one wants to own but everyone feels. And if you're leading lifecycle or growth at a consumer app, a fintech, or a subscription business, you're almost certainly living inside it right now.
What we found talking to 400+ lifecycle marketing teams
We started tracking how often this came up in our own discovery conversations, with lifecycle marketing and growth leads across consumer apps, fintech, e-commerce, and subscription businesses. These are patterns from sales calls, and the numbers reflect how often each problem came up unprompted.

Figure: Lifecycle marketing is bottlenecked before campaigns even start
2 in 5 teams run manual export-import as their core segmentation workflow
Not as a one-off workaround, as the standard, repeating process every time they need a new segment. At one wearables brand, this meant pulling from Metabase, exporting, and importing into HubSpot, despite an API connection between the two tools that no one had set up. At a consumer health brand, it was a three-step process: data team, then API, then MoEngage.
1 in 2 teams can't build a segment without manual effort or a queue
Some owned the manual work themselves. Others were waiting on a data team. Either way, no one was moving at campaign speed.
More than 1 in 3 face a structural ceiling on long-lookback segmentation
Either customer data is fragmented across three or more platforms with no unified identity, or their ESP caps data retention at 90–180 days. In several cases, both. The segment they wanted to build wasn't blocked by a missing skill. It was blocked by the tool.
1 in 5 can't measure ROI from their personalization efforts
Not because the data doesn't exist, but because attributing it requires analysis they can't access independently. One team described their AI decisioning as a "complete black box." Another said plainly: "Can't measure incremental ROI from personalization." The campaigns were running. Whether they were working was anyone's guess.
The numbers tell you the scale. Here's what's actually causing it.





Root cause #1: every audience build requires a cross-team handoff
The standard lifecycle workflow at a mid-size consumer or fintech company:
Idea → Data team ticket → SQL query → Export → Manual import into ESP → Campaign build → Launch
Each handoff is a delay. The delays compound.
At one consumer health brand, the team described it this way: segment creation requires a "data team → APIs → MoEngage workflow." Even when API connections technically exist, they often aren't wired together.
At a wearables brand, the setup was Metabase for analysis, manually exporting segments, then importing into HubSpot, "despite having an API hook between the two." The API existed. No one had set it up. The marketing team didn't have the access or context to do it themselves.

Figure: Cross-team handoff is a core bottleneck in lifecycle marketing
The tools aren't broken. They're disconnected, and nobody's job description covers the gap, but even if you fix the workflow, there's a deeper problem underneath it.
Root cause #2: data teams can't prioritize lifecycle requests over everything else
Data teams aren't withholding access. They're stretched thin, and lifecycle marketing requests sit below product analytics, infrastructure work, and compliance tickets in most sprint queues.
The wait time problem
A one-week turnaround is the norm, not the exception. At a senior care provider we spoke to, the performance marketing team flagged "current: 1 week turnaround" as their primary frustration.
That's not a failure of any individual data team. It's what happens when data engineers are simultaneously handling product analytics, infrastructure, compliance, and five other stakeholders all convinced their ticket is urgent.
What happens when marketing stops asking
Across the teams we spoke to, half couldn't build a segment without either doing it manually or waiting in a queue. So lifecycle marketers learn to work around the dependency instead, platform-native audiences, 30-day cohorts instead of behavior-based ones, broad sends instead of targeted ones.
After enough of this, they stop asking for more and make do with what they can, resulting in limited personalization and poor customer engagement.
And even if they did push for better access, the tools themselves have hard limits.
“I feel like I'm able to, in 20% of my time, execute on what normally a team of three to five full time lifecycle marketers would do — without needing engineering, data or shared resources.”
Drew Price, VP, Growth Marketing, BryteBridge Group
“I feel like I'm able to, in 20% of my time, execute on what normally a team of three to five full time lifecycle marketers would do — without needing engineering, data or shared resources.”
Drew Price, VP, Growth Marketing, BryteBridge Group
“I feel like I'm able to, in 20% of my time, execute on what normally a team of three to five full time lifecycle marketers would do — without needing engineering, data or shared resources.”
Drew Price, VP, Growth Marketing, BryteBridge Group
Root cause #3: your ESP can't reach the data it needs
The retention cap problem
Most ESPs have constraints that aren't obvious until you hit them. MoEngage and CleverTap cap data retention at 90–180 days.
Any behavioral segmentation requiring a longer lookback, users who lapsed last quarter but just showed re-engagement signals, is simply off the table inside the tool. To build those segments, you need data that lives outside the ESP entirely.
The identity fragmentation problem
Even when platforms technically support data import via API, the setup requires someone who understands both marketing logic and data schema. That person almost never exists on either team.
At companies with fragmented data stacks, customer records spread across a CRM, a support tool, an e-commerce platform, and billing — you can end up with the same user carrying three different IDs across four systems. You need a data team just to define what "customer" means.
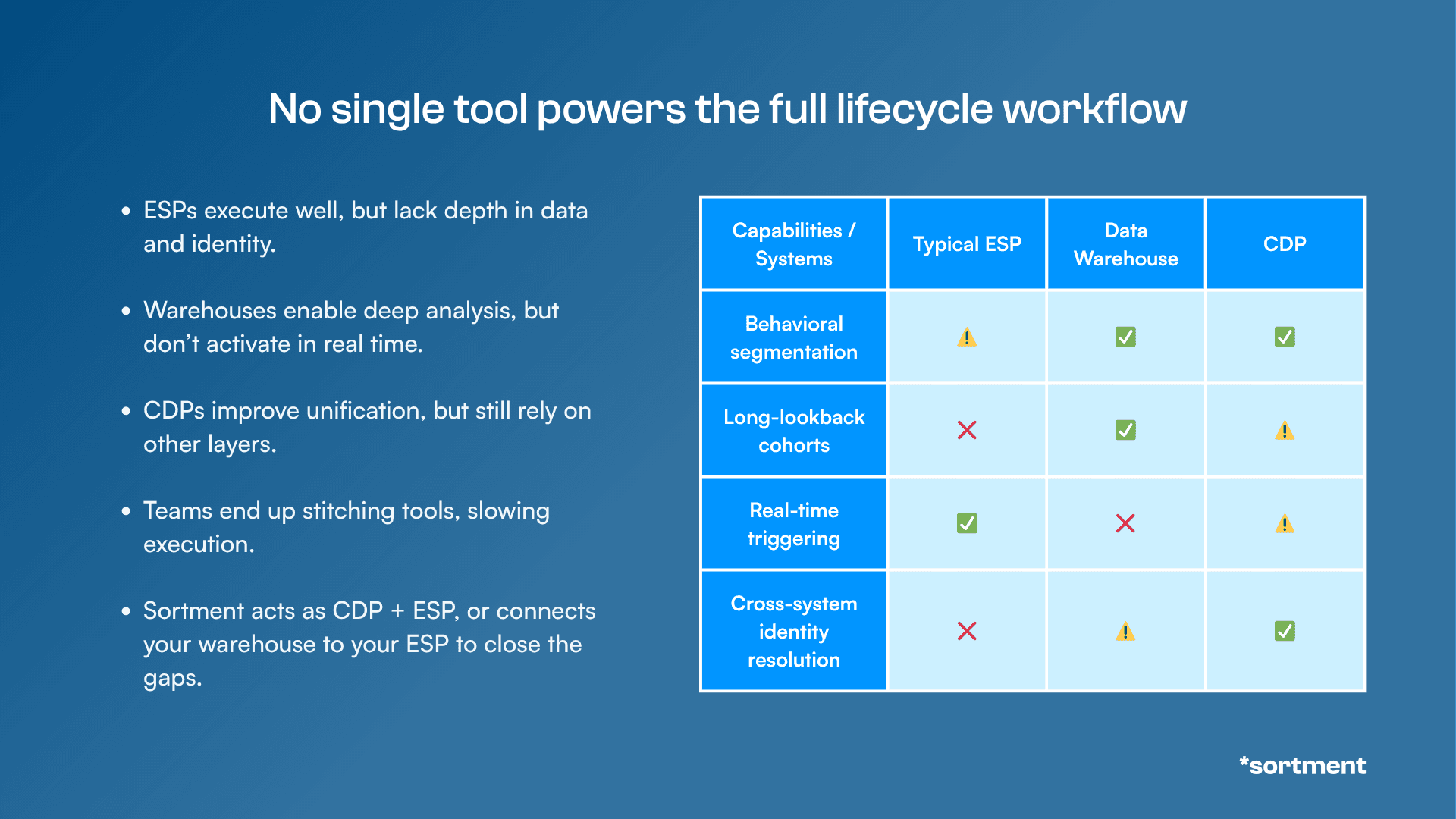
Figure: No single tool powers the full lifecycle workflow
33% of the teams had at least one of these structural ceilings. The segment wasn't blocked by a slow ticket. It was blocked by the architecture.
But sometimes the ceiling isn't technical either.
Root cause #4: data teams sometimes use complexity as a shield
In discovery conversations with one fintech company's growth team, the data person flagged schema complexity as a major concern, even though SQL queries for nearly identical use cases already existed. The pattern that surfaced repeatedly: "data professionals justify their role by emphasizing complexity."
That's not a character flaw. When a team has owned something technical for years and a new tool is offering to hand it to marketers, the instinct to protect is understandable. But the effect is the same: lifecycle teams get told self-serve isn't feasible when it often is.
When you hit this wall, it's worth asking: is this genuinely complex, or does it feel complex because no one has done the work to make it simple?
What it's costing your team
The operational friction is frustrating. The business impact is much more severe to your function's bottomline. Four places revenue leaks when lifecycle marketing can't access data:
1. Missed activation windows
When a segment takes ten days to build, the campaign that should have gone out on day one of a user's experience goes out in week two. The window is closed. The user formed their opinion on day three, you can't engage them with the stale messaging now.
2. List degradation from over-broad sends
When segmentation is hard, the default is "send to everyone." Broad, untargeted sends drive email fatigue, unsubscribes, and deliverability decay. None of it appears in a single campaign report, it accumulates quietly.
3. Unmeasured ROI from personalization
A lot of teams we spoke to couldn't measure the incremental revenue impact of their personalization efforts, not because the data didn't exist, but because attributing it required a ticket no one could justify opening. A customer put it as: "Can't measure incremental ROI from personalization."
Teams optimize on opens and clicks because that's what the platform shows them. Whether personalization is actually moving revenue stays a mystery.
4. Shrinking campaign ambition
Eventually, lifecycle teams stop proposing complex campaigns. They already know the answer: "We don't have the data for that." The ceiling on what lifecycle can achieve gets set by data team bandwidth, not marketing strategy.
These aren't isolated problems. They compound. And they all trace back to the same structural gap.
What one marketer built in a year
BryteBridge scaled a new brand from 2 states to 20 with one lifecycle marketer, no data engineering team, and Sortment.
10x
Revenue, year-over-year
2,000+
Campaigns shipped in 12 months
1
Marketer. No engineers.
What one marketer built in a year
BryteBridge scaled a new brand from 2 states to 20 with one lifecycle marketer, no data engineering team, and Sortment.
10x
Revenue, year-over-year
2,000+
Campaigns shipped in 12 months
1
Marketer. No engineers.
What one marketer built in a year
BryteBridge scaled a new brand from 2 states to 20 with one lifecycle marketer, no data engineering team, and Sortment.
10x
Revenue, year-over-year
2,000+
Campaigns shipped in 12 months
1
Marketer. No engineers.
How the teams that solved this actually did it
The companies that have broken this dependency share a pattern: they didn't start by buying a new tool. They started by restructuring how data flows to marketing.
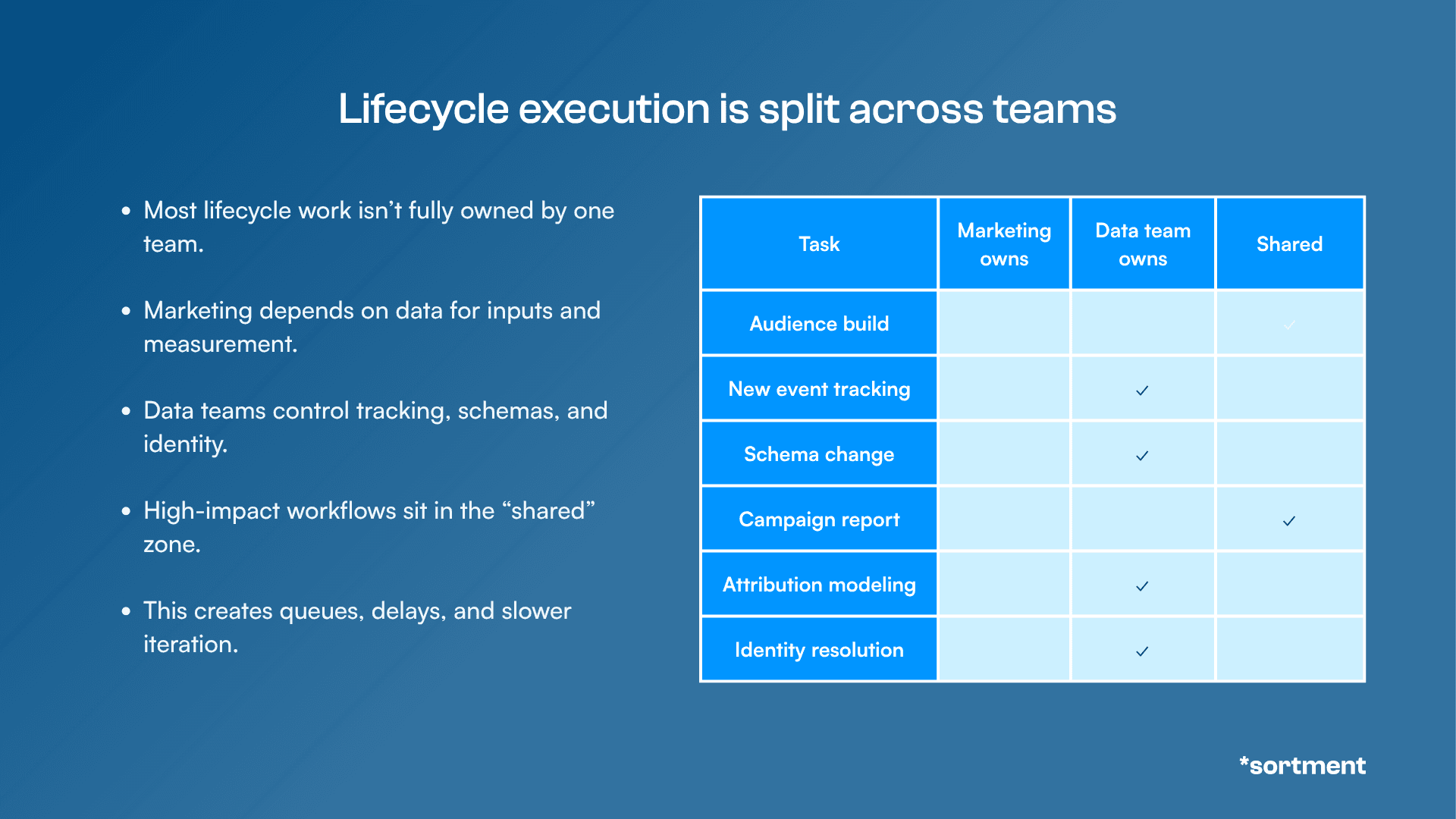
Figure: Lifecycle execution is split across teams
1. Fix identity before you fix segmentation
One company consolidated their CRM and support data into a single platform, letting them create custom attributes without touching database tables, no engineering ticket for every new property. The unlock was unified data that marketing could actually reach.
If customer records are scattered across five systems with five identity schemas, no tool purchase will fix segmentation until identity is resolved first. This is where a single source of truth such as a data warehouse (Snowflake, Redshift etc.) help.
2. Give marketers a self-serve layer, not raw access
The goal isn't to turn lifecycle marketers into SQL engineers. It's to stop making every audience build contingent on data team availability.
When a marketer can describe a segment in plain language, "users who completed onboarding in the last 30 days but haven't made a second purchase", and get an audience back in minutes, the dynamic changes entirely.
3. Instrument your data stack for marketing from the start
Most data schemas are built for product analytics, not campaign triggers. Events are named for engineers. Timestamps are stored without session context.
If your data team is building or rebuilding event tracking, lifecycle should be in the room defining which events matter for campaign logic. Retrofitting it later is expensive. Semantic layer that assigns a description to each attribute and event is crucial.
4. Define the boundary once, clearly
On the flip side, a lot of data teams name marketing requests as a top source of unplanned work. A more sustainable model: agree explicitly on what lifecycle marketing owns independently versus what needs data team involvement.
Lifecycle owns: audience builds within existing properties, campaign performance reporting, A/B test setup, new computed properties
Data team handles: schema changes, compliance-sensitive segments
When both teams know the boundary, they stop colliding on routine work, and the data team is actually available when you need them for something complex.
This is the problem Sortment was built to solve
Every fix above requires one thing: a layer between your data and your ESP that marketing can actually use, without SQL, without tickets, without waiting.
Segmentation without tickets
Sortment connects directly to your data warehouse and your ESP. Marketers describe the audience they need in plain language.
Sortment builds the query, pulls the segment, and syncs it to your campaign tool, MoEngage, HubSpot, CleverTap, wherever you're sending. No export. No import. No ticket.
Find lifecycle growth opportunities with Sortment AI
See how Strategy AI monitors your customer data, surfaces growth opportunities, and recommends campaigns tied to activation, retention, or monetization.
Find lifecycle growth opportunities with Sortment AI
See how Strategy AI monitors your customer data, surfaces growth opportunities, and recommends campaigns tied to activation, retention, or monetization.
Find lifecycle growth opportunities with Sortment AI
See how Strategy AI monitors your customer data, surfaces growth opportunities, and recommends campaigns tied to activation, retention, or monetization.
Campaign analysis without waiting
Lifecycle teams use Sortment to ask the questions that currently go unanswered: What's the average number of sessions before a user converts? Which cohorts have the highest 90-day retention? Which segments responded to the last campaign and which didn't?
Questions that currently sit in a backlog get answered in the same conversation.
The data team, freed for work that actually needs them
Sortment's Background Agents surface insights and alerts (based on your goals and business metrics). Marketing stops depending on data teams for routine audience builds and performance questions.
The data team stays involved where they should be, on infrastructure, on new data models, on governance. Both teams do the work they're actually good at.
Where to start this week
You don't need a platform change to start moving. Three things that cost nothing:
Step 1: Map your lifecycle workflow end-to-end
Count every handoff, every step that requires someone outside marketing to act before you can move forward. That count is your problem statement.
Step 2: Audit your active segments
How many are platform-native versus actually powered by your data? How many do you want to run that you don't? The gap between those two numbers is your operational cost.
Step 3: Have one direct conversation with your data team
Not to relitigate ownership, but to agree on what lifecycle genuinely needs regularly versus what should be self-serve. Most data teams would prefer fewer ad hoc requests.
Most lifecycle teams would prefer not to wait a week for an audience. There's more alignment available than the current workflow suggests.
If you want to see what it looks like when that alignment is supported by the right tooling, we'd be glad to show you how Sortment works.
See what Sortment can do in 30 days
Pick one lifecycle goal, like activation, retention, or monetization and see how Sortment can achieves your business goals.
See what Sortment can do in 30 days
Pick one lifecycle goal, like activation, retention, or monetization and see how Sortment can achieves your business goals.
See what Sortment can do in 30 days
Pick one lifecycle goal, like activation, retention, or monetization and see how Sortment can achieves your business goals.
Frequently asked questions
How many segments should a lifecycle team actually be running?
There's no fixed number, but most teams are running far fewer than they should, and the constraint is almost never strategic. If building a new segment requires a data team ticket, teams unconsciously cap themselves at whatever feels manageable to maintain manually.
A useful benchmark: if you can describe a campaign you'd want to run but can't because you don't have the audience for it, that's a segment you should be running.
What's the difference between platform-native segments and warehouse-powered ones?
Platform-native segments are built entirely from data your ESP already holds — events it tracked, attributes it stored, behavior within its own retention window. Fast to build, no external help required.
Warehouse-powered segments draw on data that lives outside the ESP: purchase history, product usage signals, CRM data, support interactions.
They're more accurate and almost always more effective — but they require a pipeline between your data store and your campaign tool, which is exactly where the data team dependency kicks in.
Do I need to replace my current ESP to use Sortment?
No. Sortment sits between your data and your existing campaign tools — it doesn't replace them.
If you're on MoEngage, CleverTap, HubSpot, or similar, Sortment connects to your data source, builds the audience, and syncs it into whichever tool you're already using to send. Your ESP stays in place. What changes is how audiences get built and how analysis gets done.
Is Sortment the same as a CDP?
No. CDPs are infrastructure — they ingest, unify, and store customer data. Sortment is an execution layer that works with data you already have, wherever it lives.
You don't need to implement a CDP before using Sortment, and for most teams at this scale, you may not need one at all.
We're a lean team without a dedicated lifecycle hire, does this work for us?
Yes. Soundverse built and scaled their entire lifecycle marketing function using Sortment without hiring a dedicated retention team — the full story is here.
Sortment's AI agents cover strategy design, content creation, and performance analysis, so lean teams can run programs that would otherwise require several specialists.
What does Sortment cost?
Pricing depends on your data volume, team size, and use case. Full details are on the pricing page.
See also
Why Frequency Capping Silently Reduces Your Email Campaign Reach
Why Frequency Capping Silently Reduces Your Email Campaign Reach
Why Frequency Capping Silently Reduces Your Email Campaign Reach
Frequency caps in lifecycle and email marketing silently suppress your most engaged users — and standard reports won't show it. Here's how it happens and how to find it before it costs you weeks of reach.
Frequency caps in lifecycle and email marketing silently suppress your most engaged users — and standard reports won't show it. Here's how it happens and how to find it before it costs you weeks of reach.
See what Sortment can do for your goals.
See what Sortment can do for your goals.
Book a 30-minute call. We'll show you how the pilot works with your data and your stack.
Book a 30-minute call. We'll show you how the pilot works with your data and your stack.
AGENTS
CASE STUDIES
RESOURCES
AGENTS
CASE STUDIES
RESOURCES
There's a conversation that happens in almost every growth team:
Marketing: "We need to launch a re-engagement campaign for users who haven't hit their first value moment."
Data: "Sure, we can get to that — probably next week?"
Probably next week is quietly killing your retention numbers.
Your lifecycle team has the strategy and the creative. Your data team has the customer intelligence locked in a warehouse. Between them sits a bottleneck that no one wants to own but everyone feels. And if you're leading lifecycle or growth at a consumer app, a fintech, or a subscription business, you're almost certainly living inside it right now.
What we found talking to 400+ lifecycle marketing teams
We started tracking how often this came up in our own discovery conversations, with lifecycle marketing and growth leads across consumer apps, fintech, e-commerce, and subscription businesses. These are patterns from sales calls, and the numbers reflect how often each problem came up unprompted.
Figure: Lifecycle marketing is bottlenecked before campaigns even start
2 in 5 teams run manual export-import as their core segmentation workflow
Not as a one-off workaround, as the standard, repeating process every time they need a new segment. At one wearables brand, this meant pulling from Metabase, exporting, and importing into HubSpot, despite an API connection between the two tools that no one had set up. At a consumer health brand, it was a three-step process: data team, then API, then MoEngage.
1 in 2 teams can't build a segment without manual effort or a queue
Some owned the manual work themselves. Others were waiting on a data team. Either way, no one was moving at campaign speed.
More than 1 in 3 face a structural ceiling on long-lookback segmentation
Either customer data is fragmented across three or more platforms with no unified identity, or their ESP caps data retention at 90–180 days. In several cases, both. The segment they wanted to build wasn't blocked by a missing skill. It was blocked by the tool.
1 in 5 can't measure ROI from their personalization efforts
Not because the data doesn't exist, but because attributing it requires analysis they can't access independently. One team described their AI decisioning as a "complete black box." Another said plainly: "Can't measure incremental ROI from personalization." The campaigns were running. Whether they were working was anyone's guess.
The numbers tell you the scale. Here's what's actually causing it.
Root cause #1: every audience build requires a cross-team handoff
The standard lifecycle workflow at a mid-size consumer or fintech company:
Idea → Data team ticket → SQL query → Export → Manual import into ESP → Campaign build → Launch
Each handoff is a delay. The delays compound.
At one consumer health brand, the team described it this way: segment creation requires a "data team → APIs → MoEngage workflow." Even when API connections technically exist, they often aren't wired together.
At a wearables brand, the setup was Metabase for analysis, manually exporting segments, then importing into HubSpot, "despite having an API hook between the two." The API existed. No one had set it up. The marketing team didn't have the access or context to do it themselves.
Figure: Cross-team handoff is a core bottleneck in lifecycle marketing
The tools aren't broken. They're disconnected, and nobody's job description covers the gap, but even if you fix the workflow, there's a deeper problem underneath it.
Root cause #2: data teams can't prioritize lifecycle requests over everything else
Data teams aren't withholding access. They're stretched thin, and lifecycle marketing requests sit below product analytics, infrastructure work, and compliance tickets in most sprint queues.
The wait time problem
A one-week turnaround is the norm, not the exception. At a senior care provider we spoke to, the performance marketing team flagged "current: 1 week turnaround" as their primary frustration.
That's not a failure of any individual data team. It's what happens when data engineers are simultaneously handling product analytics, infrastructure, compliance, and five other stakeholders all convinced their ticket is urgent.
What happens when marketing stops asking
Across the teams we spoke to, half couldn't build a segment without either doing it manually or waiting in a queue. So lifecycle marketers learn to work around the dependency instead, platform-native audiences, 30-day cohorts instead of behavior-based ones, broad sends instead of targeted ones.
After enough of this, they stop asking for more and make do with what they can, resulting in limited personalization and poor customer engagement.
And even if they did push for better access, the tools themselves have hard limits.
“I feel like I'm able to, in 20% of my time, execute on what normally a team of three to five full time lifecycle marketers would do — without needing engineering, data or shared resources.”
Drew Price, VP, Growth Marketing, BryteBridge Group
“I feel like I'm able to, in 20% of my time, execute on what normally a team of three to five full time lifecycle marketers would do — without needing engineering, data or shared resources.”
Drew Price, VP, Growth Marketing, BryteBridge Group
“I feel like I'm able to, in 20% of my time, execute on what normally a team of three to five full time lifecycle marketers would do — without needing engineering, data or shared resources.”
Drew Price, VP, Growth Marketing, BryteBridge Group
Root cause #3: your ESP can't reach the data it needs
The retention cap problem
Most ESPs have constraints that aren't obvious until you hit them. MoEngage and CleverTap cap data retention at 90–180 days.
Any behavioral segmentation requiring a longer lookback, users who lapsed last quarter but just showed re-engagement signals, is simply off the table inside the tool. To build those segments, you need data that lives outside the ESP entirely.
The identity fragmentation problem
Even when platforms technically support data import via API, the setup requires someone who understands both marketing logic and data schema. That person almost never exists on either team.
At companies with fragmented data stacks, customer records spread across a CRM, a support tool, an e-commerce platform, and billing — you can end up with the same user carrying three different IDs across four systems. You need a data team just to define what "customer" means.
Figure: No single tool powers the full lifecycle workflow
33% of the teams had at least one of these structural ceilings. The segment wasn't blocked by a slow ticket. It was blocked by the architecture.
But sometimes the ceiling isn't technical either.
Root cause #4: data teams sometimes use complexity as a shield
In discovery conversations with one fintech company's growth team, the data person flagged schema complexity as a major concern, even though SQL queries for nearly identical use cases already existed. The pattern that surfaced repeatedly: "data professionals justify their role by emphasizing complexity."
That's not a character flaw. When a team has owned something technical for years and a new tool is offering to hand it to marketers, the instinct to protect is understandable. But the effect is the same: lifecycle teams get told self-serve isn't feasible when it often is.
When you hit this wall, it's worth asking: is this genuinely complex, or does it feel complex because no one has done the work to make it simple?
What it's costing your team
The operational friction is frustrating. The business impact is much more severe to your function's bottomline. Four places revenue leaks when lifecycle marketing can't access data:
1. Missed activation windows
When a segment takes ten days to build, the campaign that should have gone out on day one of a user's experience goes out in week two. The window is closed. The user formed their opinion on day three, you can't engage them with the stale messaging now.
2. List degradation from over-broad sends
When segmentation is hard, the default is "send to everyone." Broad, untargeted sends drive email fatigue, unsubscribes, and deliverability decay. None of it appears in a single campaign report, it accumulates quietly.
3. Unmeasured ROI from personalization
A lot of teams we spoke to couldn't measure the incremental revenue impact of their personalization efforts, not because the data didn't exist, but because attributing it required a ticket no one could justify opening. A customer put it as: "Can't measure incremental ROI from personalization."
Teams optimize on opens and clicks because that's what the platform shows them. Whether personalization is actually moving revenue stays a mystery.
4. Shrinking campaign ambition
Eventually, lifecycle teams stop proposing complex campaigns. They already know the answer: "We don't have the data for that." The ceiling on what lifecycle can achieve gets set by data team bandwidth, not marketing strategy.
These aren't isolated problems. They compound. And they all trace back to the same structural gap.
What one marketer built in a year
BryteBridge scaled a new brand from 2 states to 20 with one lifecycle marketer, no data engineering team, and Sortment.
10x
Revenue, year-over-year
2,000+
Campaigns shipped in 12 months
1
Marketer. No engineers.
What one marketer built in a year
BryteBridge scaled a new brand from 2 states to 20 with one lifecycle marketer, no data engineering team, and Sortment.
10x
Revenue, year-over-year
2,000+
Campaigns shipped in 12 months
1
Marketer. No engineers.
What one marketer built in a year
BryteBridge scaled a new brand from 2 states to 20 with one lifecycle marketer, no data engineering team, and Sortment.
10x
Revenue, year-over-year
2,000+
Campaigns shipped in 12 months
1
Marketer. No engineers.
How the teams that solved this actually did it
The companies that have broken this dependency share a pattern: they didn't start by buying a new tool. They started by restructuring how data flows to marketing.
Figure: Lifecycle execution is split across teams
1. Fix identity before you fix segmentation
One company consolidated their CRM and support data into a single platform, letting them create custom attributes without touching database tables, no engineering ticket for every new property. The unlock was unified data that marketing could actually reach.
If customer records are scattered across five systems with five identity schemas, no tool purchase will fix segmentation until identity is resolved first. This is where a single source of truth such as a data warehouse (Snowflake, Redshift etc.) help.
2. Give marketers a self-serve layer, not raw access
The goal isn't to turn lifecycle marketers into SQL engineers. It's to stop making every audience build contingent on data team availability.
When a marketer can describe a segment in plain language, "users who completed onboarding in the last 30 days but haven't made a second purchase", and get an audience back in minutes, the dynamic changes entirely.
3. Instrument your data stack for marketing from the start
Most data schemas are built for product analytics, not campaign triggers. Events are named for engineers. Timestamps are stored without session context.
If your data team is building or rebuilding event tracking, lifecycle should be in the room defining which events matter for campaign logic. Retrofitting it later is expensive. Semantic layer that assigns a description to each attribute and event is crucial.
4. Define the boundary once, clearly
On the flip side, a lot of data teams name marketing requests as a top source of unplanned work. A more sustainable model: agree explicitly on what lifecycle marketing owns independently versus what needs data team involvement.
Lifecycle owns: audience builds within existing properties, campaign performance reporting, A/B test setup, new computed properties
Data team handles: schema changes, compliance-sensitive segments
When both teams know the boundary, they stop colliding on routine work, and the data team is actually available when you need them for something complex.
This is the problem Sortment was built to solve
Every fix above requires one thing: a layer between your data and your ESP that marketing can actually use, without SQL, without tickets, without waiting.
Segmentation without tickets
Sortment connects directly to your data warehouse and your ESP. Marketers describe the audience they need in plain language.
Sortment builds the query, pulls the segment, and syncs it to your campaign tool, MoEngage, HubSpot, CleverTap, wherever you're sending. No export. No import. No ticket.
Find lifecycle growth opportunities with Sortment AI
See how Strategy AI monitors your customer data, surfaces growth opportunities, and recommends campaigns tied to activation, retention, or monetization.
Find lifecycle growth opportunities with Sortment AI
See how Strategy AI monitors your customer data, surfaces growth opportunities, and recommends campaigns tied to activation, retention, or monetization.
Find lifecycle growth opportunities with Sortment AI
See how Strategy AI monitors your customer data, surfaces growth opportunities, and recommends campaigns tied to activation, retention, or monetization.
Campaign analysis without waiting
Lifecycle teams use Sortment to ask the questions that currently go unanswered: What's the average number of sessions before a user converts? Which cohorts have the highest 90-day retention? Which segments responded to the last campaign and which didn't?
Questions that currently sit in a backlog get answered in the same conversation.
The data team, freed for work that actually needs them
Sortment's Background Agents surface insights and alerts (based on your goals and business metrics). Marketing stops depending on data teams for routine audience builds and performance questions.
The data team stays involved where they should be, on infrastructure, on new data models, on governance. Both teams do the work they're actually good at.
Where to start this week
You don't need a platform change to start moving. Three things that cost nothing:
Step 1: Map your lifecycle workflow end-to-end
Count every handoff, every step that requires someone outside marketing to act before you can move forward. That count is your problem statement.
Step 2: Audit your active segments
How many are platform-native versus actually powered by your data? How many do you want to run that you don't? The gap between those two numbers is your operational cost.
Step 3: Have one direct conversation with your data team
Not to relitigate ownership, but to agree on what lifecycle genuinely needs regularly versus what should be self-serve. Most data teams would prefer fewer ad hoc requests.
Most lifecycle teams would prefer not to wait a week for an audience. There's more alignment available than the current workflow suggests.
If you want to see what it looks like when that alignment is supported by the right tooling, we'd be glad to show you how Sortment works.
See what Sortment can do in 30 days
Pick one lifecycle goal, like activation, retention, or monetization and see how Sortment can achieves your business goals.
See what Sortment can do in 30 days
Pick one lifecycle goal, like activation, retention, or monetization and see how Sortment can achieves your business goals.
See what Sortment can do in 30 days
Pick one lifecycle goal, like activation, retention, or monetization and see how Sortment can achieves your business goals.
Frequently asked questions
How many segments should a lifecycle team actually be running?
There's no fixed number, but most teams are running far fewer than they should, and the constraint is almost never strategic. If building a new segment requires a data team ticket, teams unconsciously cap themselves at whatever feels manageable to maintain manually.
A useful benchmark: if you can describe a campaign you'd want to run but can't because you don't have the audience for it, that's a segment you should be running.
What's the difference between platform-native segments and warehouse-powered ones?
Platform-native segments are built entirely from data your ESP already holds — events it tracked, attributes it stored, behavior within its own retention window. Fast to build, no external help required.
Warehouse-powered segments draw on data that lives outside the ESP: purchase history, product usage signals, CRM data, support interactions.
They're more accurate and almost always more effective — but they require a pipeline between your data store and your campaign tool, which is exactly where the data team dependency kicks in.
Do I need to replace my current ESP to use Sortment?
No. Sortment sits between your data and your existing campaign tools — it doesn't replace them.
If you're on MoEngage, CleverTap, HubSpot, or similar, Sortment connects to your data source, builds the audience, and syncs it into whichever tool you're already using to send. Your ESP stays in place. What changes is how audiences get built and how analysis gets done.
Is Sortment the same as a CDP?
No. CDPs are infrastructure — they ingest, unify, and store customer data. Sortment is an execution layer that works with data you already have, wherever it lives.
You don't need to implement a CDP before using Sortment, and for most teams at this scale, you may not need one at all.
We're a lean team without a dedicated lifecycle hire, does this work for us?
Yes. Soundverse built and scaled their entire lifecycle marketing function using Sortment without hiring a dedicated retention team — the full story is here.
Sortment's AI agents cover strategy design, content creation, and performance analysis, so lean teams can run programs that would otherwise require several specialists.
What does Sortment cost?
Pricing depends on your data volume, team size, and use case. Full details are on the pricing page.